How to create a Rmarkdown template for multiple translations ?
In my post “Rmarkdown conditional chunks to create multilingual pdf and html with images”, I proposed a way to create a rmarkdown document to be printed in two different languages. If you deal with more than two languages, your document may become difficult to read. Moreover, if you work with external people to translate your content, you neither want them to get into your rmarkdown code, nor do you want to copy-paste manually each paragraph of your document.
Instead, you may want to propose them an Excel file with one column being the original language and the second column being their translation. In that way, they do not have to care about the template.
Using the same idea than my previous post, you can use chunks to read the dataframe and care about the template after the translations are done.
The simplified Rmd template that you can use as a basis for your translation rmarkdown document is here on my github.
Define the output language
Define the output language in the rmarkdown document.
If you are working with pdf outputs, you may also want to modify lang: 'en' in the YAML header.
# Define the output language
lang <- "en"Create dataframe with translations
Here, I create the translation dataframe directly in R and save it as lang.csv. In your case, this can directly be any csv (or Excel) file.
# Create an external dataframe of translation
# Col-1 is original language ("en" here)
# Col-2 is translation
trans.df <- data.frame(
en = c("First title",
"This is a long paragraph, with different ponctuations ! We can also add the content of a list in the document as follows:",
"item 1",
"item 2",
"item 3", "subitem 3",
"item(s)"),
fr = c("Premier titre",
" Ceci est un long paragraphe, avec différentes ponctuations ! Nous pouvons aussi y ajouter le contenu d'une liste comme ci-dessous : ",
"élément 1",
"élément 2",
"élément 3",
"sous-élément 3",
"élément(s)"))
# Save it with a name that contains the lang attribute
readr::write_csv(trans.df, path = file.path(tempdir(), paste0(lang, ".csv")))Read the external table file
We read the table as if it was an external file (indeed that’s the case). I remove the possible multiple spaces and any space before or after the sequence to avoid any mis-interpretation by markdown (I added some in the French translation for the example).
trans.df <- readr::read_csv(file.path(tempdir(), paste0(lang, ".csv")))
# Remove space if before or after the text sequence
trans.df <- trans.df %>%
mutate_all(function(.) gsub("[[:space:]]{2,}", " ", .)) %>%
mutate_all(function(.) gsub("^[[:space:]]*|[[:space:]]*$", "", .)) %>%
as.data.frame()
knitr::kable(trans.df)| en | fr |
|---|---|
| First title | Premier titre |
| This is a long paragraph, with different ponctuations ! We can also add the content of a list in the document as follows: | Ceci est un long paragraphe, avec différentes ponctuations ! Nous pouvons aussi y ajouter le contenu d’une liste comme ci-dessous : |
| item 1 | élément 1 |
| item 2 | élément 2 |
| item 3 | élément 3 |
| subitem 3 | sous-élément 3 |
| item(s) | élément(s) |
The translated part of the document
With the original way I proposed for translation, you have to create a chunk specifically for the original language (so that you can see in which section of your document you are) and a chunk for the translation.
Note that text sequences have been separated when they require different formatting. Note also that cat is used with sep = "".
This is the chunk for original text and its output
```{r title1_orig, eval=(lang == "en"), results='asis'}
cat('
#### First title
This is a long paragraph, with different ponctuations ! We can also add the content of a list in the document as follows:
- item 1
- item 2
- item 3
+ subitem 3
', sep = "")
```First title
This is a long paragraph, with different ponctuations ! We can also add the content of a list in the document as follows:
- item 1
- item 2
- item 3
- subitem 3
This is the chunk for translated text and its output
lang <- "fr" ```{r title1_tr, eval=(lang != "en"), results='asis'}
cat('
#### ', trans.df[1, lang], '
', trans.df[2, lang], '
- ', trans.df[3, lang], '
- ', trans.df[4, lang], '
- ', trans.df[5, lang], '
+ ', trans.df[6, lang], '
', sep = "")
```Premier titre
Ceci est un long paragraphe, avec différentes ponctuations ! Nous pouvons aussi y ajouter le contenu d’une liste comme ci-dessous :
- élément 1
- élément 2
- élément 3
- sous-élément 3
Translation with a unique chunk
This would be nicer to use a unique chunk for both original and translation. Moreover, if you have last minute changes, you don’t want to change all line numbers. Let’s create a vector of original translations and use it as reference to find translations. This is cleaner.
tr.orig <- trans.df[,"en"]Obviously, you could do the same with inline code, like `r trans.df[tr.orig == "example text", lang]`, but personnaly speaking, I prefer using cat and asis in a chunk because:
- Syntax coloration with rstudio allows to highlight only the text in the chunk, whereas everything is blue with inline-R code.
- This allows to directly insert R command outputs without additionnal
`r`in the middle of a sentence (to add a number for instance). - Indeed, this avoids a lot of
`r`(although I use'', ..., '').
We can compare both code, in case we use a calculated variable in R (nb).
# Define nb and increment in the text
nb <- 0The unique chunk (and its output) is then the following one
Syntax coloration in rstudio:
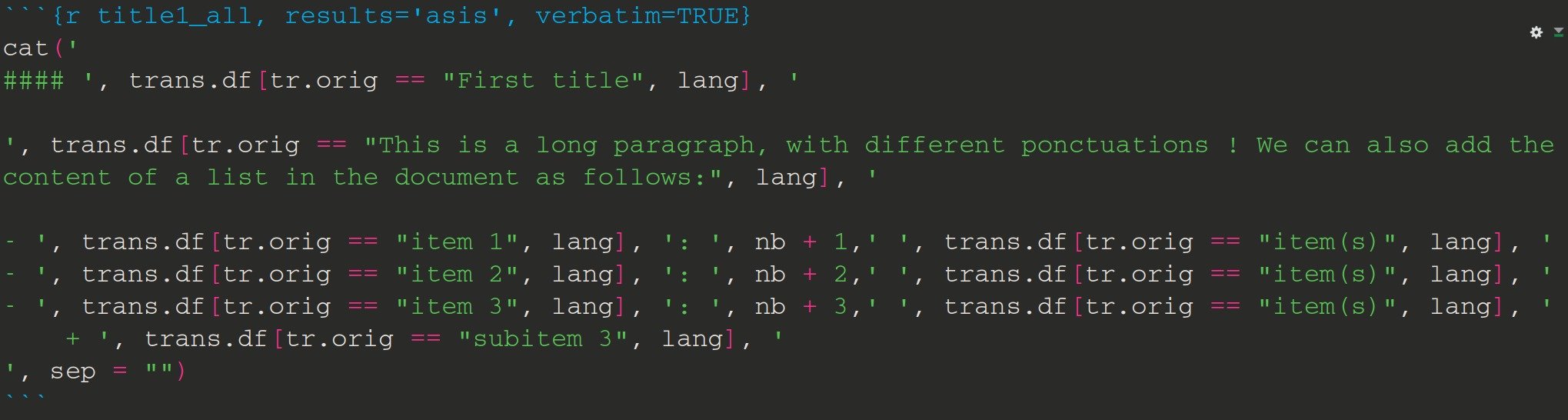
```{r title1_all, results='asis'}
cat('
##### ', trans.df[tr.orig == "First title", lang], '
', trans.df[tr.orig == "This is a long paragraph, with different ponctuations ! We can also add the content of a list in the document as follows:", lang], '
- ', trans.df[tr.orig == "item 1", lang], ': ', nb + 1,' ', trans.df[tr.orig == "item(s)", lang], '
- ', trans.df[tr.orig == "item 2", lang], ': ', nb + 2,' ', trans.df[tr.orig == "item(s)", lang], '
- ', trans.df[tr.orig == "item 3", lang], ': ', nb + 3,' ', trans.df[tr.orig == "item(s)", lang], '
+ ', trans.df[tr.orig == "subitem 3", lang], '
', sep = "")
```Premier titre
Ceci est un long paragraphe, avec différentes ponctuations ! Nous pouvons aussi y ajouter le contenu d’une liste comme ci-dessous :
- élément 1: 1 élément(s)
- élément 2: 2 élément(s)
- élément 3: 3 élément(s)
- sous-élément 3
Comparison with the inline code version
Syntax coloration in rstudio:

Chunk:
##### `r trans.df[tr.orig == "First title", lang]`
`r trans.df[tr.orig == "This is a long paragraph, with different ponctuations ! We can also add the content of a list in the document as follows:", lang]`
- `r trans.df[tr.orig == "item 1", lang]`: `r nb + 1` `r trans.df[tr.orig == "item(s)", lang]`
- `r trans.df[tr.orig == "item 2", lang]`: `r nb + 2` `r trans.df[tr.orig == "item(s)", lang]`
- `r trans.df[tr.orig == "item 3", lang]`: `r nb + 3` `r trans.df[tr.orig == "item(s)", lang]`
+ `r trans.df[tr.orig == "subitem 3", lang]`:Retrieve all translations and create table for translators
What is great with the unique chunk way is that we can extract all text to be translated and create an empty table for translators. You may want to remove repeated texts in the translation using unique. Here, we use the present rmarkdown document that I use to create this blog article.
thisfile <- readr::read_lines("2017-10-06-translation-rmarkdown-documents-using-data-frame.Rmd")
# Find lines with translations
all_trans <- thisfile[grep('trans.df\\[tr.orig == "', thisfile)]
# Extract translations
empty.file <- purrr::map(
strsplit(all_trans, 'trans.df\\[tr.orig == "'), ~.x[2:length(.x)]) %>%
unlist() %>%
purrr::map_chr(~strsplit(.x, '", lang]', fixed = TRUE)[[1]][1]) %>%
unique() %>%
data.frame(en = ., translation = "")
# Show empty file
knitr::kable(empty.file)| en | translation |
|---|---|
| example text | |
| First title | |
| This is a long paragraph, with different ponctuations ! We can also add the content of a list in the document as follows: | |
| item 1 | |
| item(s) | |
| item 2 | |
| item 3 | |
| subitem 3 |
Then you can save this empty file.
# Save empty translation file
readr::write_csv(empty.file, path = "myemptyfile.csv")After that, you can imagine everything you want:
- integrate more formatting like italic, bold, …
- updating a table of translation to only send the missing translations to your translators
- use a table with multiple columns for all translations
- …
Be creative !
The simplified Rmd template that you can use as a basis for your translation rmarkdown document is here on my github.
You can also contact me for your projects like these or any other project !
Citation:
For attribution, please cite this work as:
Rochette Sébastien. (2017, Oct. 06). "Translation of rmarkdown documents using a data frame". Retrieved from https://statnmap.com/2017-10-06-translation-rmarkdown-documents-using-data-frame/.
BibTex citation:
@misc{Roche2017Trans,
author = {Rochette Sébastien},
title = {Translation of rmarkdown documents using a data frame},
url = {https://statnmap.com/2017-10-06-translation-rmarkdown-documents-using-data-frame/},
year = {2017}
}