L’an dernier, j’ai participé à un défi d’analyse des données de l’enquête Kaggle. L’objectif du défi : raconter une histoire sur les données d’un sous-ensemble de la communauté de la science des données représentée dans cette enquête, par une combinaison de texte narratif et d’exploration de données. J’ai profité de cette occasion pour faire des cartes choroplèthes ternaires avec {ggtern} et {tricolore}.
Choix de l’histoire
J’espère que mon blog montre de manière suffisamment claire que je suis un développeur R qui aime les cartes. En tant que spécialiste des données (certains diront data scientist), je m’intéresse particulièrement aux questions de communication et de reproductibilité des études. R, la cartographie et la reproductibilité sont mes lignes directrice pour l’exploration des données de l’enquête Kaggle.
Je vais essayer de voir s’il y a des disparités géographiques mondiales dans le panel des répondants. Je me concentrerai sur les langages de programmation les plus utilisés par les personnes ayant répondu. Par chance (?), R est l’un de ces langages…
# Path to data
# extraWD <- file.path("data/")
path <- extraWDPackages R utilisés
J’ai utilisé différents packages pour la manipulation des données et la cartographie. Les nouveautés pour moi sont {ggtern}, {tricolore} et {rnaturalearth}.
library(readr)
library(tidyr)
library(maps)
library(mapdata)
library(maptools) # required to transform map object as sf
library(dplyr)
library(ggplot2)
library(sf)
library(purrr)
library(stringr)
library(mapview)
library(glue)
library(tricolore)
library(forcats)
library(ggtern)
library(rnaturalearth)Palettes de couleurs personnalisées
Je crée mes propres palettes de couleurs pour les figures à venir.
bluepal <- colorRampPalette(
c("#FFFFFF", "#D9F0F5", "#B2E2EC", "#8CD3E3", "#288EA5", "#1A5F6E"))
orangebluepal <- colorRampPalette(
c(rev(c("#F8DFD8", "#F1C0B0", "#EBA18A", "#B4421E", "#782C14")),
c("#FFFFFF", "#D9F0F5", "#B2E2EC", "#8CD3E3", "#288EA5", "#1A5F6E")))
catpal <- c("#DE633C", "#41B7D1", "#A6AAAB", "#FF9919", "#C0504D", "#5B5960", "#EEECE1")
par(mfrow = c(1, 3))
barplot(rep(1, 6), col = bluepal(6), space = 0)
barplot(rep(1, 6), col = orangebluepal(6), space = 0)
barplot(rep(1, 7), col = catpal, space = 0)
Lecture et sélection des données
J’ai choisi de travailler avec les réponses à choix multiples qui contiennent des informations sur le pays d’origine, de telle sorte qu’on puisse dessiner des cartes.
mcr <- read_csv(file.path(path, 'multipleChoiceResponses.csv'), skip = 1) Nettoyage des noms de colonnes et quelques regex
Pour simplifier la manipulation des questions qui m’intéressent, j’ai réduit le nom des colonnes. J’ai utilisé quelques regex pour extraire les noms des langages de programmation dans les questions à choix multiples (et ouvertes) pour pouvoir les récupérer plus facilement dans l’exploration. La manipulation des chaînes de caractères est facile avec {stringr} et devient puissante quand on sait se servir des expressions régulières….
## Programming languages
questions <- tibble(value = names(mcr)) %>%
mutate(col_name = case_when(
grepl("In which country", value) ~ "country",
grepl("What is your age (# years)?", value) ~ "age",
grepl("What programming languages do you use", value) ~
paste0("lang_use_all_", str_extract(value, '(?<=Choice - )(\\w*\\s*[:graph:]*)*$')),
grepl("What specific programming language do you use most often?", value) ~ "lang_use_often",
grepl("What programming language would you recommend", value) ~ "lang_recommend",
grepl("primary tool", value) ~ paste0("tool_", str_extract(value, '(?<= - )(.*)(?= - Text$)')),
grepl("IDE", value) ~ paste0("IDE_", str_extract(value, '(?<=Choice - )(\\w*\\s*[:graph:]*)*$')),
grepl("your work easy to reproduce", value) ~ paste0("repro_how_", str_extract(value, '(?<= Choice - )(\\w*\\s*[:graph:]*)*$')),
grepl("reuse and reproduce", value) ~ paste0("repro_barrier_", str_extract(value, '(?<= Choice - )(\\w*\\s*[:graph:]*)*$')),
grepl("which specific data visualization library", value) ~ "dataviz_often",
grepl("Which types of data", value) ~ paste0("datatype_all_", str_extract(value, '(?<= Choice - )(\\w*\\s*[:graph:]*)*$')),
grepl("What is the type of data", value) ~ "datatype_often",
# grepl("cloud computing services"),
TRUE ~ value
))
# Duplicated colnames are open answers
questions$col_name[duplicated(questions$col_name)] <-
paste0(questions$col_name[duplicated(questions$col_name)], "_open")
names(mcr) <- questions$col_name
# Clean names
questions## # A tibble: 395 x 2
## value col_name
## <chr> <chr>
## 1 Duration (in seconds) Duration (in seconds)
## 2 What is your gender? - Selected Choice What is your gender? - Selected Choice
## 3 What is your gender? - Prefer to self… What is your gender? - Prefer to self…
## 4 What is your age (# years)? age
## 5 In which country do you currently res… country
## 6 What is the highest level of formal e… What is the highest level of formal e…
## 7 Which best describes your undergradua… Which best describes your undergradua…
## 8 Select the title most similar to your… Select the title most similar to your…
## 9 Select the title most similar to your… Select the title most similar to your…
## 10 In what industry is your current empl… In what industry is your current empl…
## # … with 385 more rowsPréparation des cartes pour une jointure par noms de pays
J’aime utiliser le package {sf} pour manipuler les données spatiales (Vous pouvez en savoir plus sur la façon de l’utiliser avec mon tutoriel rapide sur {sf}). Dans la première version de cet article, j’ai utilisé la carte du monde incluse dans le package {maps} comme fond de carte. Pour l’utiliser au format {sf}, j’ai dû modifier partiellement la fonction st_as_sf pour récupérer les noms de pays et de régions de l’objet map. La fonction st_as_sf_sf originale peut traiter les fichiers {map} mais ne récupère que la variable “region”.
# Get world map data
worldmap <- maps::map("world", fill = TRUE, plot = FALSE)
# Rewrite st_as_sf for map object to get subregions
st_as_sf.map <- function(x, ...) {
# browser()
ID0 = vapply(strsplit(x$names, ":"), function(y) y[1], "")
ID1 = vapply(strsplit(x$names, ":"), function(y) y[2], "")
ID_unique <- 1:length(ID0)
m.sp = maptools::map2SpatialPolygons(x, IDs = ID_unique, proj4string = sp::CRS("+init=epsg:4326"))
m = st_as_sf(m.sp)
m$ID = as.numeric(vapply(m.sp@polygons, function(x) slot(x, "ID"), ""))
m$region = ID0[m$ID]
m$subregion = ID1[m$ID]
m
}
# Transform to Winkel tripel projection for World representation
worldmap_sf <- worldmap %>%
st_as_sf.map()
plot(worldmap_sf)
La transformation d’un objet {maps} en objet {sf} fonctionne parfaitement. Cependant, il est préférable de représenter des cartes du monde avec une projection ayant la plus petite distorsion possible. J’ai donc décidé d’utiliser la nouvelle projection “Equal Earth”. Comme expliqué dans l’article de Matt Strimas-Mackey, la projection “Equal Earth” est maintenant disponible dans les dernières versions de proj. Je travaille sur Ubuntu et ma principale ressource linux pour les outils de cartographie est le PPA UbuntuGIS. Grâce au merveilleux travail de cette petite équipe UbuntuGIS, la version 5.2 de proj est disponible pour ma distribution (bionic). Au passage, j’ai écrit un tutoriel sur le blog de ThinkR si vous voulez savoir comment installer R et les packages de cartographie sur Ubuntu 18.04.
Quoi qu’il en soit, le problème est que la projection de ma carte du monde n’est pas parfaite.
worldmap_sf %>%
st_transform("+proj=eqearth +wktext") %>%
ggplot() +
geom_sf(aes(geometry = geometry))![]()
Du coup, dans cette nouvelle version d’article (par rapport à ma soumission Kaggle), j’ai changé ma source pour utiliser la carte du monde du package {rnaturalearth}, qui, de fait, peut être récupérée directement en format {sf}.
ne_world <- rnaturalearth::ne_countries(scale = 50, returnclass = "sf")
world_eqe <- ne_world %>%
st_transform("+proj=eqearth +wktext") world_eqe %>%
ggplot() +
geom_sf(aes(geometry = geometry)) J’ai modifié les noms des pays pour qu’ils soient nommés de manière identique dans la carte et dans le jeu de données. Les personnes qui ont choisi “Autre” ou “Je ne souhaite pas divulguer ma localisation” ne seront pas visible sur les cartes.
J’ai modifié les noms des pays pour qu’ils soient nommés de manière identique dans la carte et dans le jeu de données. Les personnes qui ont choisi “Autre” ou “Je ne souhaite pas divulguer ma localisation” ne seront pas visible sur les cartes.
# List countries not written identically in both datasets
mcr %>%
mutate(is_in_map = country %in% world_eqe$name_long) %>%
filter(!is_in_map) %>%
pull(country) %>%
unique()## [1] "United States of America"
## [2] "Other"
## [3] "Iran, Islamic Republic of..."
## [4] "United Kingdom of Great Britain and Northern Ireland"
## [5] "Russia"
## [6] "I do not wish to disclose my location"
## [7] "South Korea"
## [8] "Hong Kong (S.A.R.)"
## [9] "Viet Nam"# Rename countries on the map for correspondance
world_eqe_country <- world_eqe %>%
mutate(country = case_when(
name_long == "Republic of Korea" ~ "South Korea",
subunit == "Hong Kong S.A.R." ~ "Hong Kong (S.A.R.)",
name_long == "Vietnam" ~ "Viet Nam",
# sovereignt == "Czechia" ~ "Czech Republic",
name_long == "Russian Federation" ~ "Russia",
TRUE ~ name_long
))
# Rename countries in the data for correspondance
mcr_country <- mcr %>%
mutate(country = case_when(
country == "Republic of Korea" ~ "South Korea",
country == "United States of America" ~ "United States",
country == "United Kingdom of Great Britain and Northern Ireland" ~ "United Kingdom",
country == "Iran, Islamic Republic of..." ~ "Iran",
TRUE ~ country
))
# Test again # List countries not written identically in both datasets
# mcr_country %>%
# mutate(is_in_map = country %in% world_eqe_country$country) %>%
# filter(!is_in_map) %>%
# pull(country) %>%
# unique()Exploration
Nombre de réponses par pays
On va peut-être pouvoir passer à l’exploration maintenant !
Il y a de grandes disparités dans le panel des répondants. Les pays les plus représentés sont les États-Unis et l’Inde. La carte permet de voir que très peu de pays d’Afrique sont représentés. L’échelle est une échelle logarithmique, ce qui signifie que les disparités entre les pays sont bien plus grandes que ce que laisse supposer cette carte.
mcr_count <- mcr_country %>%
count(country) %>%
arrange(desc(n))
# Combine area with centroid to avoid under-represented countries
world_eqe_country %>%
st_union(by_feature = TRUE) %>%
group_by(country) %>%
summarise(do_union = FALSE) %>%
left_join(mcr_count, by = "country") %>%
filter(!is.na(n)) %>%
st_centroid(of_largest_polygon = TRUE) %>%
ggplot() +
# geom_sf(data = worldmap_sf %>% left_join(mcr_count, by = "country"), aes(fill = n)) +
geom_sf(data = world_eqe_country, aes(geometry = geometry), fill = "black") +
geom_sf(aes(colour = n, size = n, geometry = geometry), show.legend = "point") +
scale_colour_gradientn("n", colours = bluepal(6), trans = "log10") +
scale_fill_gradientn("n", colours = bluepal(6), trans = "log10") +
scale_size(trans = "log10", range = c(0.5, 5)) +
coord_sf(crs = st_crs(world_eqe_country)) +
ggtitle("Number of answers by country (log scale)") +
theme(panel.background = element_rect(fill = "#383838"))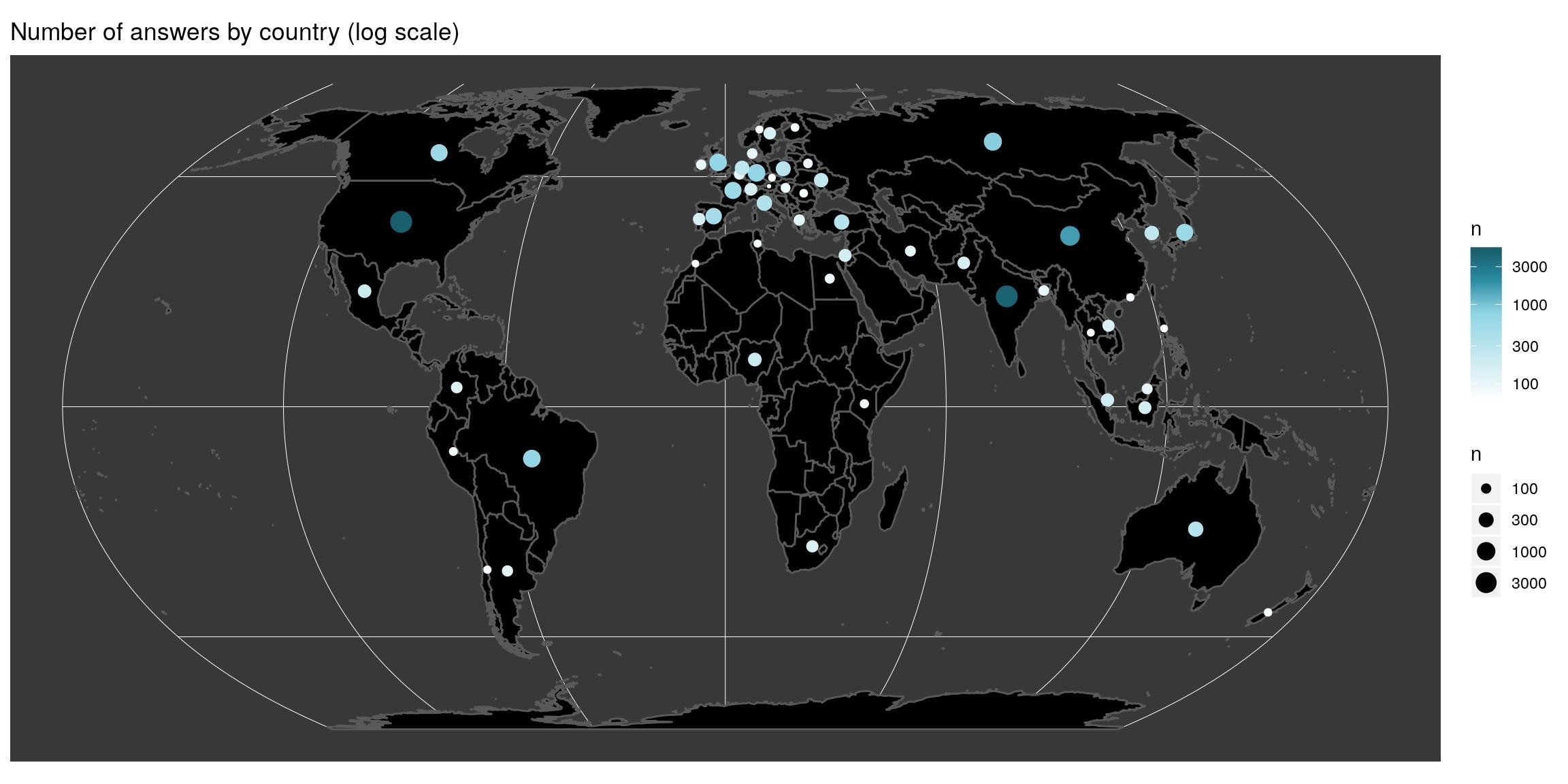
Fonction pour créer une carte ternaire
Lorsque la balance est fortement déséquilibrée vers l’une des trois possibilités, la couleur de sortie peut sembler homogène. Dans la suite, j’ai envie de mettre en évidence les zones dans lesquelles la réponse moyenne d’un pays s’écarte de la réponse moyenne mondiale. Pour ça, je dois calculer la moyenne mondiale et ajuster l’écart-type de l’échelle (trichromique) des couleurs à celle des données. C’est le but de la fonction ci-dessous.
#' Create ternary map
#' @param most data.frame with columns named value and n
#' @param q_country data.frame with country and value columns
#' @param p_legend Vector of 3 names for triangle legend
#' @param join_map The sf map to join dataset with
#' @param title title of the graph
#' @param top indices of the three values to keep
map_triangle <- function(most, q_country, p_legend, join_map, title, top = 1:3) {
# browser()
# clean_names <- most$value[top] %>%
# make.names()
#
# Keep only three indices
top <- top[1:3]
# Number of respondant by country of three most used
x_country <- q_country %>%
filter(value %in% most$value[top]) %>%
count(country, value)
x_country_spread <- x_country %>%
spread(value, n) %>%
mutate_at(vars(most$value[top]), list(~ifelse(is.na(.), 0, .))) # dplyr >= 0.8
# mutate_at(vars(most$value[top]), funs(ifelse(is.na(.), 0, .))) # dplyr < 0.8
# Whole data mean
center <- apply(x_country_spread %>% select(most$value[top]), 2, mean)
center <- center / sum(center)
# As spatial
x_sf <- x_country_spread %>%
left_join(join_map, ., by = "country")
# Scaling factor
sum_prop <- t(apply(x_country_spread %>% select(most$value[top]), 1, function(x) x/sum(x)))
mins <- apply(sum_prop, 2, min)
zoomed_side <- (1 - (mins[2] + mins[3])) - mins[1]
true_spread <- 1 / zoomed_side
# Triangle colors
triangle <- Tricolore(x_sf, p1 = most$value[top][1], p2 = most$value[top][2], p3 = most$value[top][3],
label_as = "pct", center = center,
spread = true_spread)
# Triangle legend
triangle_legend <- triangle$key +
labs(L = p_legend[1], T = p_legend[2], R = p_legend[3]) +
theme(
tern.axis.arrow.show = TRUE,
plot.background = element_rect(fill = NA, color = NA),
axis.title = element_text(size = 10))
# Map
x_sf %>%
mutate(rgb = triangle$rgb) %>%
ggplot() +
geom_sf(aes(fill = rgb, geometry = geometry), size = 0.1) +
coord_sf(crs = st_crs(x_sf)) +
scale_fill_identity() +
# triangle scale annotation
annotation_custom(
ggtern::ggplotGrob(triangle_legend),
xmin = st_bbox(x_sf)[1] + 0.01*(st_bbox(x_sf)[3] - st_bbox(x_sf)[1]),
xmax = st_bbox(x_sf)[1] + 0.35*(st_bbox(x_sf)[3] - st_bbox(x_sf)[1]),
ymin = st_bbox(x_sf)[2] + 0.01*(st_bbox(x_sf)[4] - st_bbox(x_sf)[2]),
ymax = st_bbox(x_sf)[2] + 0.50*(st_bbox(x_sf)[4] - st_bbox(x_sf)[2])
) +
ggtitle(c(title, ""))
}R, python ou SQL ?
Langage de programmation utilisé
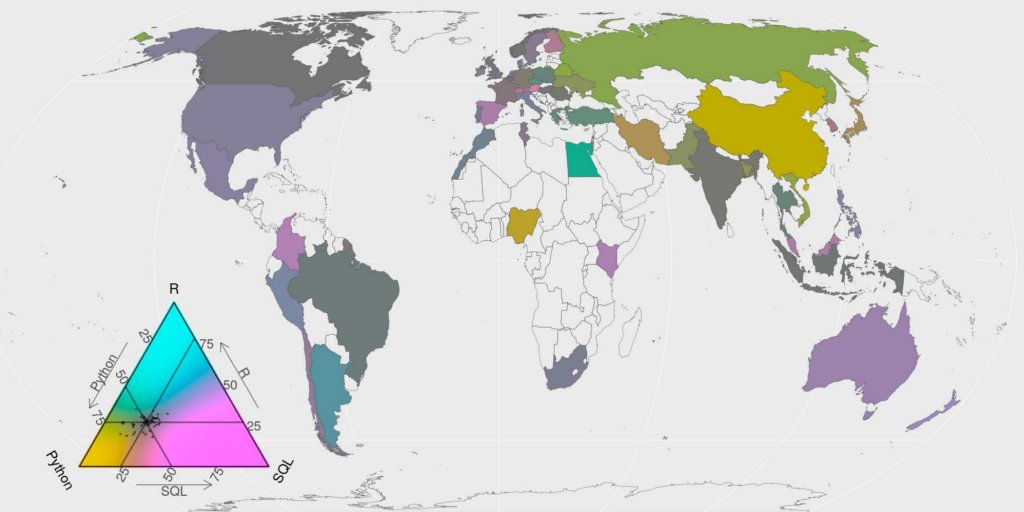
J’ai utilisé la question à choix multiples “Quels langages de programmation utilisez-vous?” pour trouver les trois langages de programmation les plus utilisés. Selon les répondants, il s’agit de Python, SQL et R.
lang_country <- mcr_country %>%
select(country, starts_with("lang_use_all")) %>%
gather(key, value, -country) %>%
filter(value != -1)
# most_used
most_used <- lang_country %>%
count(value) %>%
filter(!is.na(value)) %>%
arrange(desc(n))
most_used## # A tibble: 322 x 2
## value n
## <chr> <int>
## 1 Python 15711
## 2 SQL 8267
## 3 R 6685
## 4 C/C++ 4383
## 5 Java 3999
## 6 Javascript/Typescript 3249
## 7 Bash 2708
## 8 MATLAB 2652
## 9 C#/.NET 1670
## 10 Visual Basic/VBA 1274
## # … with 312 more rowsJe sais que SQL n’est pas vraiment utilisé dans le même contexte que python ou R, mais on peut quand même regarder l’équilibre entre ces trois là. Et explorons-le géographiquement. On calcule le total de fois où chaque langage a été choisi, séparément dans chaque pays. La carte montre la répartition entre ces trois langage les plus utilisées. Les couleurs montrent les écarts par rapport à la moyenne (Noter la balance des couleurs dans la légende du triangle. Elle est tourné vers la réponse moyenne). Bien sûr, l’équilibre est biaisé en faveur de python, mais il y a quelques pays avec une proportion plus élevée de R (bleu-rose) et SQL (rose-rose) par rapport à la moyenne mondiale.
map_triangle(most = most_used, q_country = lang_country,
p_legend = c('Python', 'R', 'SQL'),
join_map = world_eqe_country,
title = "Proportion of respondant by country of first three languages used",
top = 1:3)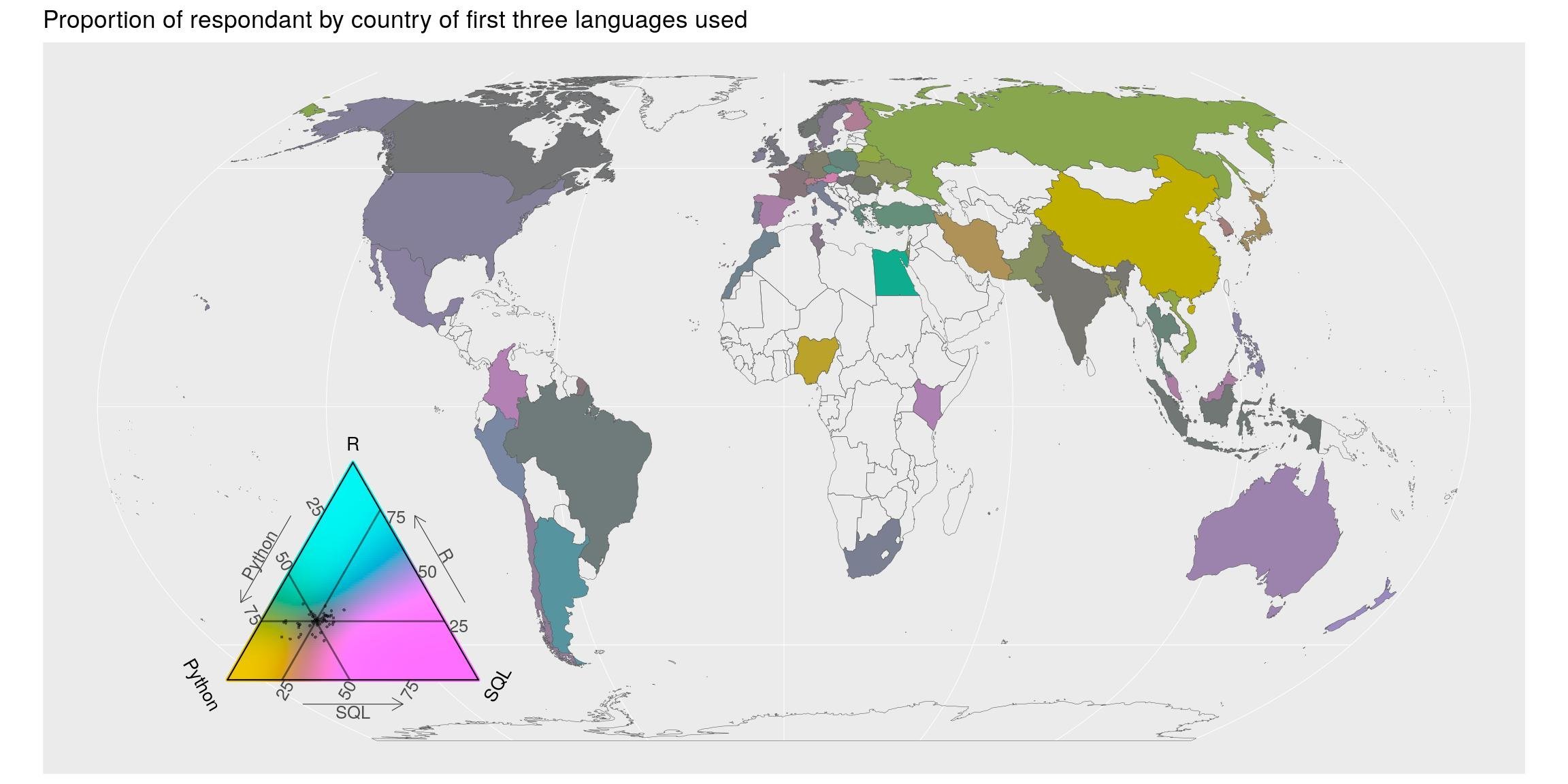
Langage le plus souvent utilisé
La question précédente comptait toutes les langues utilisées par les répondants. À la question “Quel langage de programmation spécifique utilisez-vous le plus souvent ?”, il n’y a qu’une seule réponse possible. Dans ce cas, python est toujours premier mais R est deuxième, avant SQL.
lang_often_country <- mcr_country %>%
select(country, starts_with("lang_use_often")) %>%
gather(key, value, -country) %>%
filter(!is.na(value))
# most_often
most_often <- lang_often_country %>%
count(value) %>%
arrange(desc(n))
most_often## # A tibble: 90 x 2
## value n
## <chr> <int>
## 1 -1 23746
## 2 Python 8180
## 3 R 2046
## 4 SQL 1211
## 5 Java 903
## 6 C/C++ 739
## 7 C#/.NET 432
## 8 Javascript/Typescript 408
## 9 MATLAB 355
## 10 SAS/STATA 228
## # … with 80 more rowsLa carte montre la proportion du premier langage utilisé parmi les répondants de chaque pays. Les couleurs mettent en avant les écarts par rapport à la moyenne. Géographiquement parlant, il semble y avoir plus d’utilisateurs de python en Russie et en Chine. Les pays européens, océaniens sont plus “R” que la moyenne mondiale tandis que l’Amérique et l’Australie sont plus utilisateurs de R+SQL que la moyenne mondiale. Encore une fois, notez la balance des couleurs dans la légende du triangle. Ils sont tournés vers la réponse moyenne.
map_triangle(
most = most_often, q_country = lang_often_country,
p_legend = c('Python', 'R', 'SQL'),
join_map = world_eqe_country,
title = "Proportion of language most often used among the three first languages",
top = 2:4)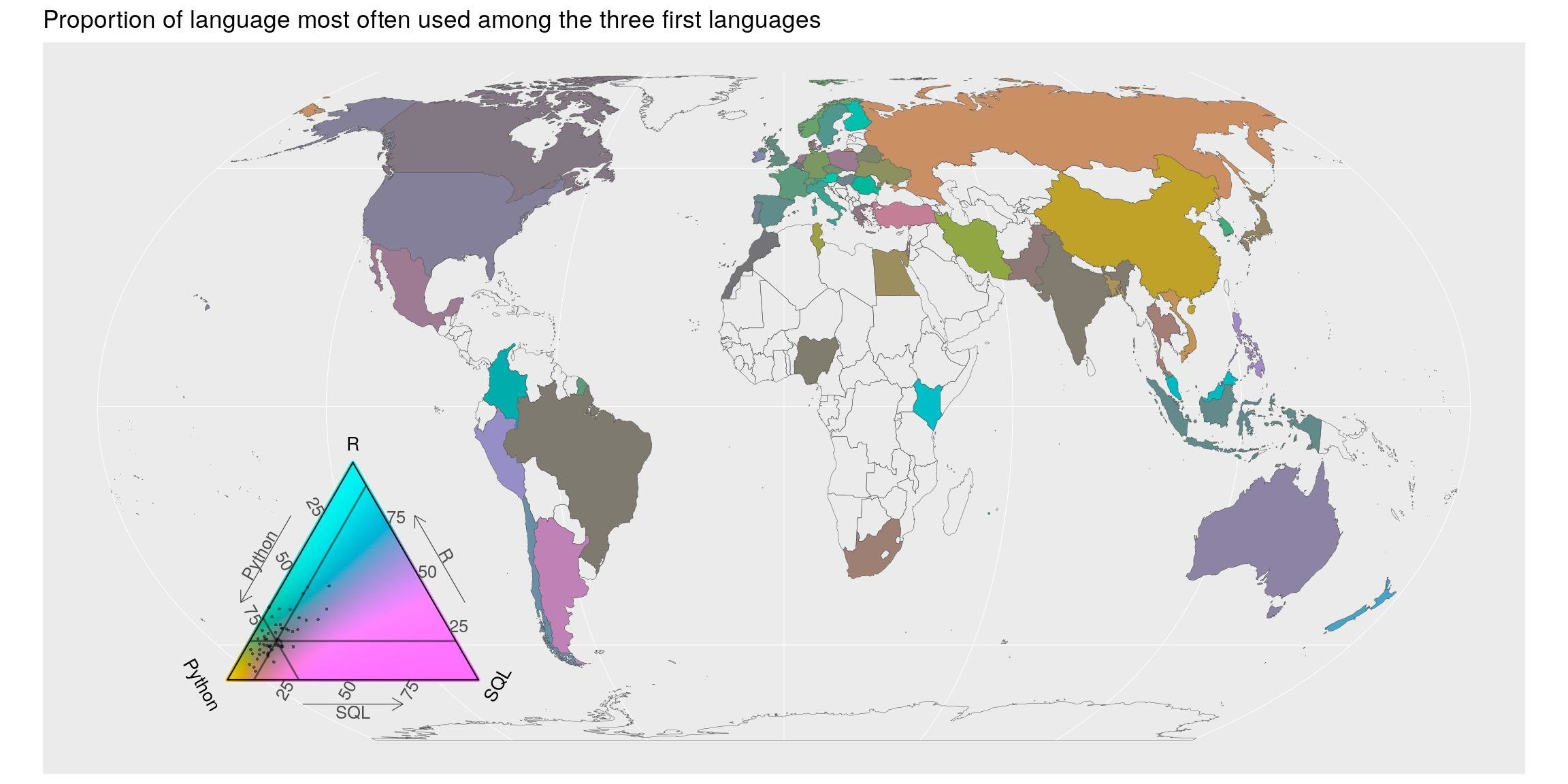
Langage de programmation recommandé
Je me suis demandé si les développeurs recommandaient plutôt leur langage préféré ou un autre. Voyons les 10 premiers langages recommandés par les utilisateurs des 6 premiers langages utilisés (-1 = aucun, inclus).
lang_often_country <- mcr_country %>%
select(country, starts_with("lang_use_often"), starts_with("lang_recommend")) %>%
mutate(lang_use_often = ifelse(is.na(lang_use_often)|lang_use_often == "Other", lang_use_often_open, lang_use_often),
lang_recommend = ifelse(is.na(lang_recommend)|lang_recommend == "Other", lang_recommend_open, lang_recommend))
lang_often_country %>%
group_by(lang_use_often, lang_recommend) %>%
summarise(nb = n()) %>%
left_join(most_often, by = c("lang_use_often" = "value")) %>%
arrange(desc(nb)) %>%
mutate(prop = nb/n) %>%
# filter(prop < 1, n > 100) %>%
group_by(lang_use_often) %>%
top_n(10) %>%
arrange(desc(prop)) %>%
mutate(recommend = paste(lang_use_often, lang_recommend, sep = " => ")) %>%
mutate(recommend = fct_reorder(recommend, prop)) %>%
filter(lang_use_often %in% most_often$value[1:6]) %>%
ggplot() +
geom_col(aes( fct_reorder(recommend, prop), prop, fill = prop)) +
coord_flip() +
scale_fill_gradientn("prop", colours = bluepal(6)) +
facet_wrap(~fct_reorder(lang_use_often, nb), scales = "free_y") +
labs(x = "", y = "", title = "Language recommendation knowing most used language") +
theme_bw() +
theme(panel.background = element_rect(fill = "#292929"),
panel.grid.major.y = element_blank(),
panel.grid.minor.x = element_blank()
)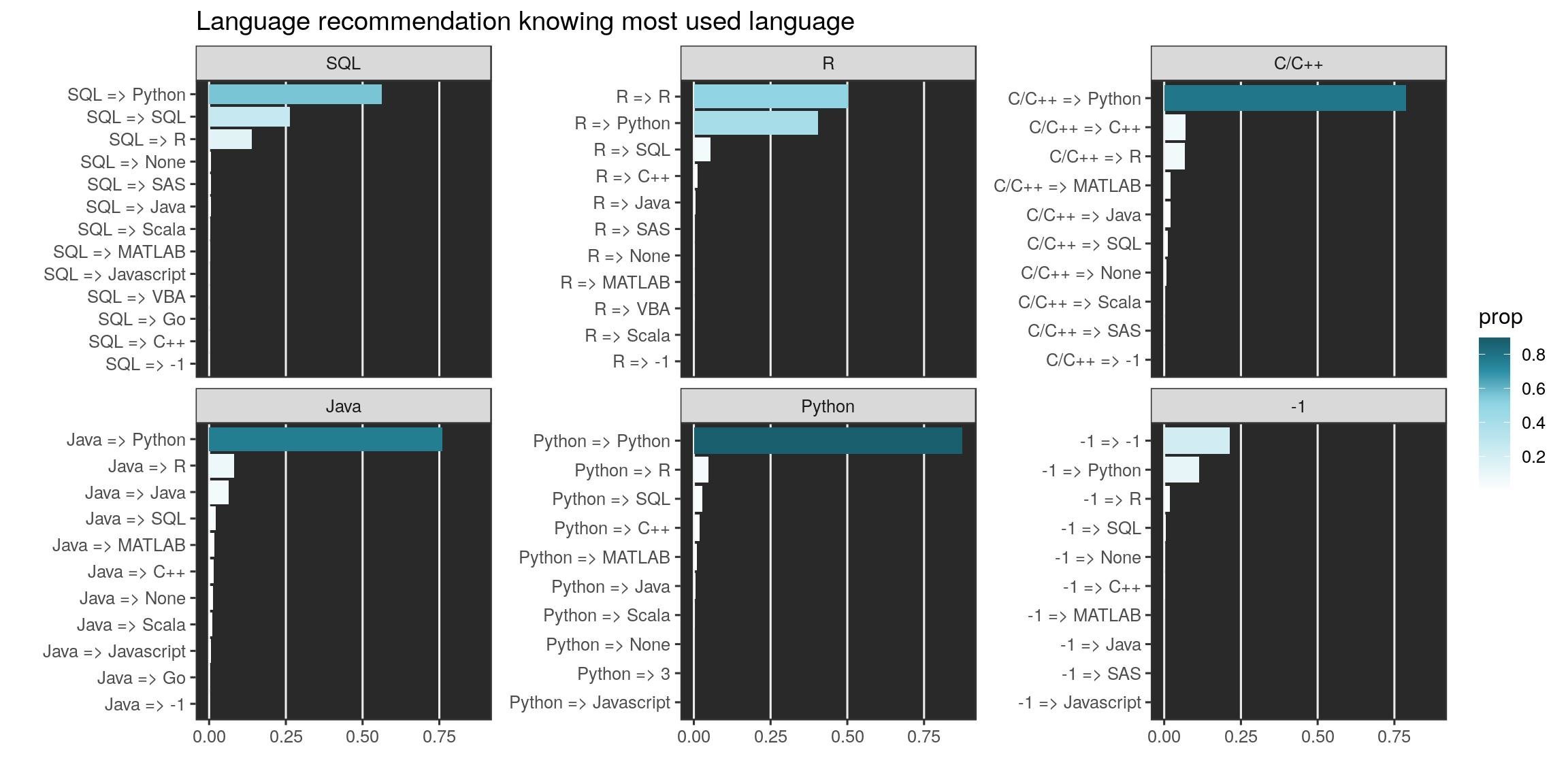
On peut réduire encore aux six premiers langages (-1 est pour aucune langue). À l’exception des utilisateurs de R, c’est plutôt python qui est recommandé dans ce panel. Les utilisateurs de python ne recommandent d’ailleurs presque que python. Les propositions des utilisateurs R est plus équilibré comme celui des utilisateurs SQL.
lang_often_country %>%
group_by(lang_use_often, lang_recommend) %>%
summarise(nb = n()) %>%
mutate(lang_summary = case_when(
lang_use_often == lang_recommend ~ lang_recommend,
lang_recommend %in% most_often$value[1:6] ~ lang_recommend,
TRUE ~ "Other"
)) %>%
filter(lang_use_often %in% most_often$value[1:6]) %>%
left_join(most_often, by = c("lang_use_often" = "value")) %>%
arrange(desc(nb)) %>%
ggplot() +
geom_bar(aes(fct_reorder(lang_use_often, n), nb,
fill = fct_reorder(lang_summary, nb)),
stat = "identity", position = "fill") +
coord_flip() +
scale_fill_manual("most\nrecommended", values = catpal) +
labs(x = "Most used language", y = "Proportion", title = "Language recommendation knowing most used language") +
theme(legend.position = "bottom") +
theme_bw()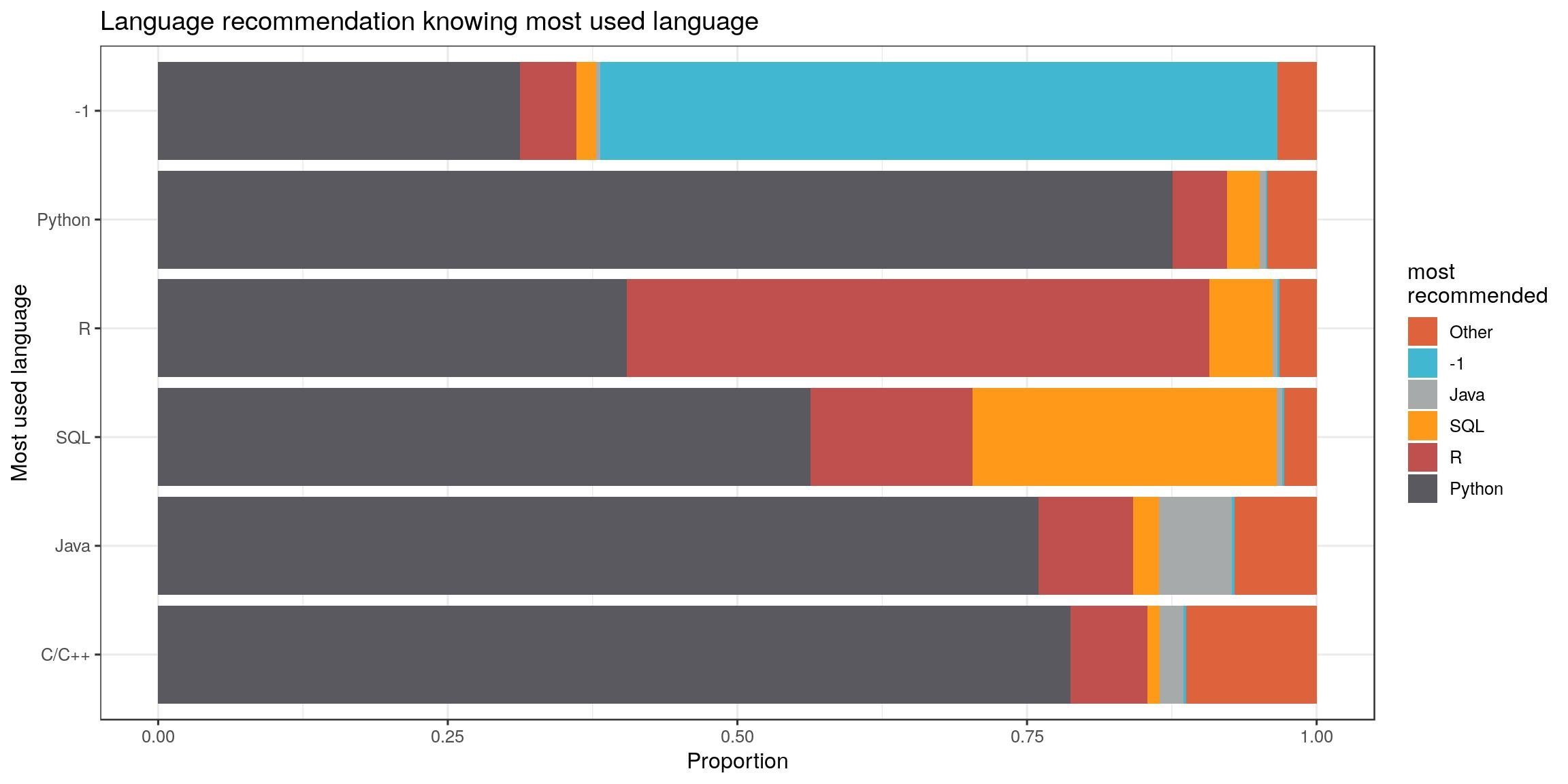
Reproductibilité - les bonnes méthodes
Que pensent les répondants des bonnes méthodes pour la reproductibilité ?
La documentation est la première réponse. J’aurai répondu la même chose. C’est la raison pour laquelle j’ai l’habitude de recommander une approche “Rmarkdown-first” pour les analyses de données mais aussi pour le développement (package R). Cela oblige les développeurs à penser aux utilisateurs, mais aussi à eux-mêmes dans quelques mois…
La deuxième réponse est un “code lisible par un humain”. Si les répondants n’étaient que des utilisateurs de R, je dirais que Rstudio a fait un excellent travail pour que les gens réalisent à quel point un code lisible est beaucoup plus facile à comprendre. Mais ici, la majorité des répondants sont des développeurs python, ce qui suggère que la lisibilité est une préoccupation pour les autres langages aussi. Il semblerait que le {tidyverse} aille dans la bonne direction.
repro_how_country <- mcr_country %>%
select(country, starts_with("repro_how_")) %>%
gather(key, value, -country) %>%
filter(!is.na(value))
# most_repro_how
most_repro_how <- repro_how_country %>%
count(value) %>%
arrange(desc(n))
most_repro_how## # A tibble: 181 x 2
## value n
## <chr> <int>
## 1 -1 23689
## 2 Make sure the code is well documented 8052
## 3 Make sure the code is human-readable 7781
## 4 Share code on Github or a similar code-sharing repository 5636
## 5 Define all random seeds 4614
## 6 Share both data and code on Github or a similar code-sharing repository 4566
## 7 Include a text file describing all dependencies 4366
## 8 Define relative rather than absolute file paths 3665
## 9 Share data, code, and environment using a hosted service (Kaggle Kerne… 2945
## 10 Share data, code, and environment using containers (Docker, etc.) 2680
## # … with 171 more rowsMettons cela en carte pour les 3 premières méthodes recommandées (sauf la valeur = -1). A l’exception de quelques pays, les trois premières méthodes sont importantes : la proportion est d’environ 1/3 pour tous (couleur grise). Les répondants des pays plutôt bleus, principalement situés en Europe, pensent que la troisième réponse (partage de code) est un peu moins importante.
map_triangle(
most = most_repro_how, q_country = repro_how_country,
p_legend = c('a1', 'a2', 'a3'),
join_map = world_eqe_country,
title = "Proportion of the three best ways for reproducibility",
top = 2:4)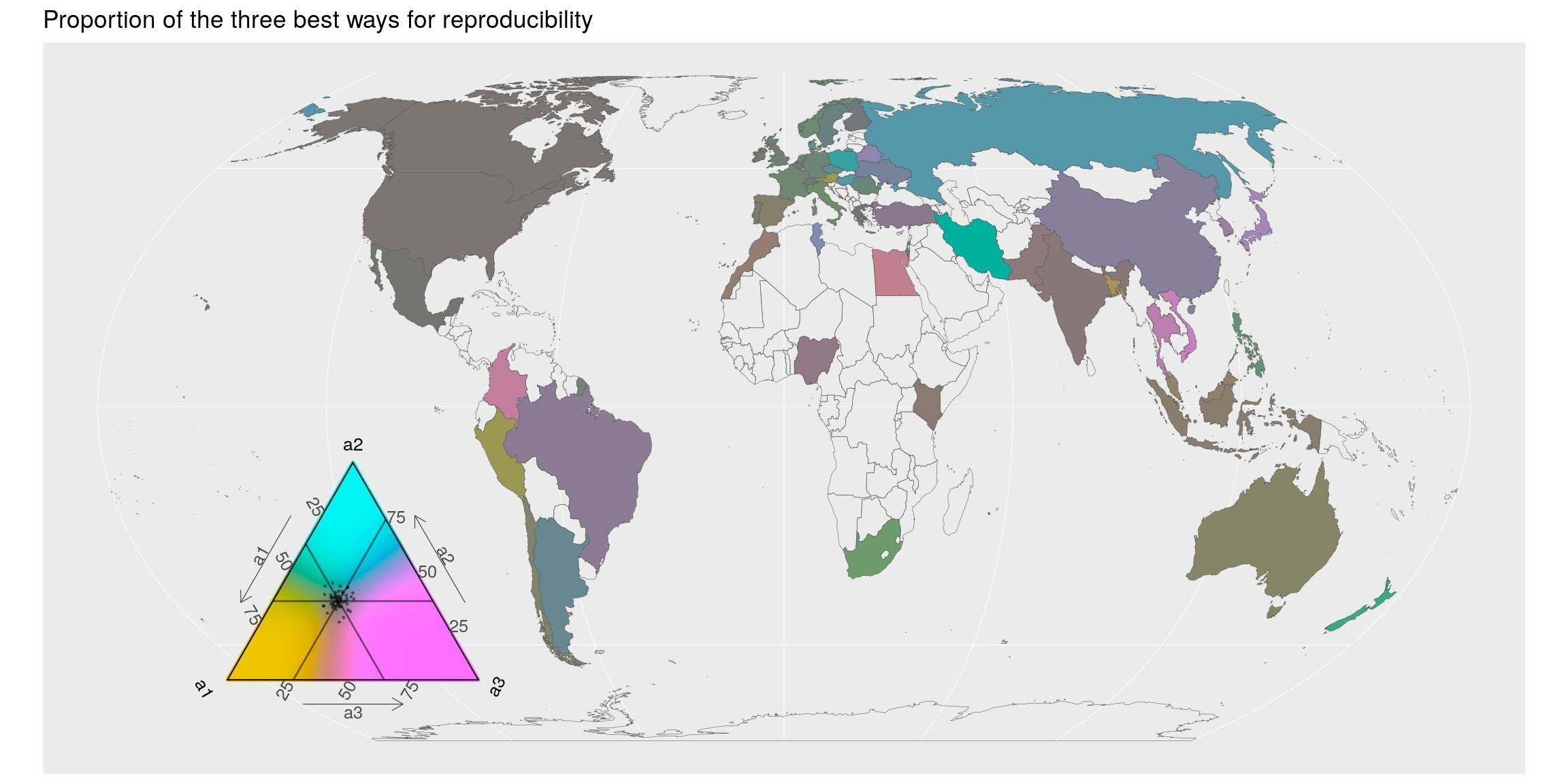
Reproductibilité - obstacles
Que pensent-ils des obstacles à la reproductibilité ?
S’assurer d’une certaine reproductibilité prend beaucoup de temps. C’est sûr. Si vous passez du temps à écrire de la documentation, vous n’êtes pas en train de développer. Mais est-ce que ça n’en vaut pas la peine ?
repro_barriers_country <- mcr_country %>%
select(country, starts_with("repro_barrier_")) %>%
gather(key, value, -country) %>%
filter(!is.na(value))
# most_repro_how
most_barriers_how <- repro_barriers_country %>%
count(value) %>%
arrange(desc(n))
most_barriers_how## # A tibble: 417 x 2
## value n
## <chr> <int>
## 1 -1 23428
## 2 Too time-consuming 6478
## 3 Not enough incentives to share my work 3569
## 4 Requires too much technical knowledge 2674
## 5 None of these reasons apply to me 2500
## 6 Afraid that others will use my work without giving proper credit 2104
## 7 Too expensive 1371
## 8 I had never considered making my work easier for others to reproduce 1059
## 9 Other 520
## 10 120 4
## # … with 407 more rowsD’un point de vue géographique, la plupart des pays s’accordent sur les deux premiers obstacles. La barrière des connaissances techniques (pays plutôt rose) semble être plus importante pour l’Afrique, l’Asie du Sud et l’Océanie.
Concernant R, je dirais qu’avec {rmarkdown}, la documentation ne nécessite pas vraiment de connaissances techniques. Cependant, je vois encore des utilisateurs de R qui n’ont jamais entendu parler des documents Rmd. Il est de notre devoir de les informer et de continuer de communiquer à ce sujet. Ça change tellement la vie. En plus, avec {reticulate} ou Apache arrow, même les utilisateurs python peuvent utiliser les documents Rmarkdown. L’avenir sera probablement fait d’un plus grand nombre de flux de travail conçus avec une combinaison de langages de programmation…
map_triangle(
most = most_barriers_how, q_country = repro_barriers_country,
p_legend = c('b1', 'b2', 'b3'),
join_map = world_eqe_country,
title = "Proportion of the three biggest barriers to reproducibility",
top = 2:4)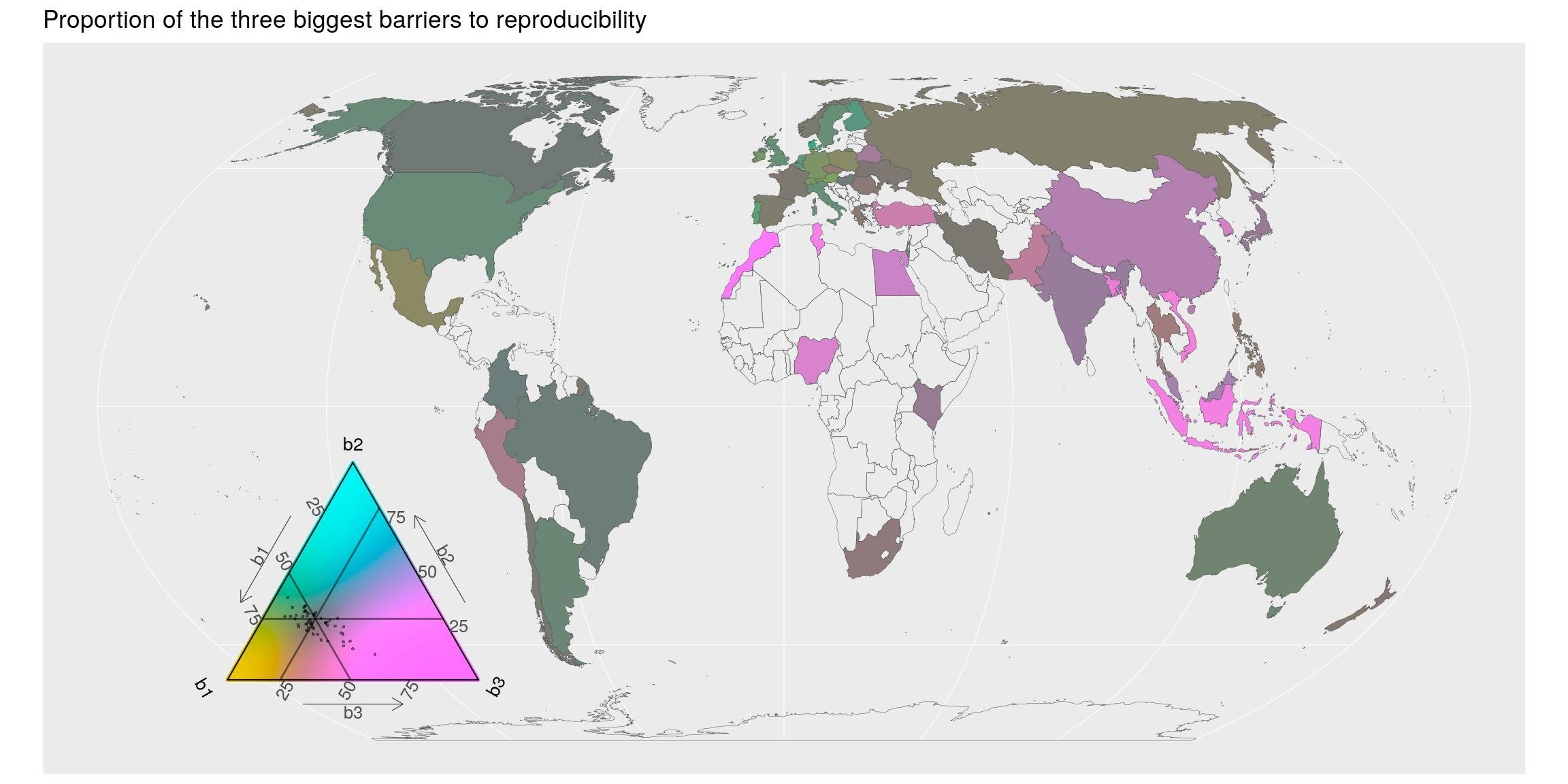
Discussion
Pour moi, l’exercice était plutôt une nouvelle bonne raison de jouer avec des packages R que je ne connaissais pas avant. Je ne tirerai pas de grandes conclusions au sujet de cette enquête menée auprès d’un groupe particulier de personnes, mais elle soulève des questions intéressantes. En effet, bien que le nombre de personnes interrogées ne soit pas le même d’un pays à l’autre, il semble y avoir des tendances par continent dans les réponses.
Python est toujours le langage le plus utilisé parmi les répondants. R est juste derrière. Ces deux langage sont de bons langages pour la science des données (data science) et l’apprentissage automatique (machine learning). Je ne suis pas vraiment surpris qu’ils soient parmi les plus utilisés.
Cependant, je ne m’attendais pas à ce que SQL soit un langage autant représenté. Dans un sens, c’est logique car d’énormes jeux de données sont utilisés pour le machine learning et ils sont généralement stockés dans des bases de données.
Mais aujourd’hui, des langages comme R (sûrement python aussi) facilitent l’interaction avec les bases de données, comme s’il s’agissait de simples fichiers csv sur notre ordinateur. Les packages comme {DBI}, {dbplyr}, {sparklyr} sont de bons exemples dans ce sens.
Du coup, je ne serais pas surpris si, à l’avenir, le nombre de personnes utilisant réellement SQL devient plus faible parmi les répondants de telles enquêtes orientées machine learning users.
Par ailleurs, les cartes montrent quelques écarts régionaux par rapport à l’utilisation moyenne mondiale de logiciels comme python. L’Europe et l’Océanie semblent plus à même d’utiliser R que l’Amérique ou que l’Asie. Mais je ne crois pas qu’on puisse tirer de réelles conclusions à ce sujet sans mieux comprendre les profils des répondants.
Il faudrait aussi essayer de comprendre pourquoi il y a si peu de répondants dans les pays africains. La barrière technique est peut-être l’une des réponses, comme le suggère la dernière carte sur la reproductibilité.
En ce qui concerne les cartes ternaires, j’aime avoir la possibilité de tracer des proportions entre trois catégories, mais j’ai beaucoup de difficultés à lire les valeurs exactes des proportions dans le triangle des couleurs…
Pour finir, je pense que ma principale satisfaction avec cet article de blog, c’est l’utilisation d’une projection du monde qui n’est pas Mercator !
Vous pouvez trouver le script R complet de cet article sur mon Github nommé Blog Tips repository.
Citation :
Merci de citer ce travail avec :
Rochette Sébastien. (2019, mars. 20). "Enquête Kaggle 2018: Cartes des langages de programmation et répartition des problèmes de reproductibilité". Retrieved from https://statnmap.com/fr/2019-03-20-enquete-kaggle-2018-cartes-des-langages-de-programmation-et-repartition-des-problemes-de-reproductibilite/.
Citation BibTex :
@misc{Roche2019Enquê,
author = {Rochette Sébastien},
title = {Enquête Kaggle 2018: Cartes des langages de programmation et répartition des problèmes de reproductibilité},
url = {https://statnmap.com/fr/2019-03-20-enquete-kaggle-2018-cartes-des-langages-de-programmation-et-repartition-des-problemes-de-reproductibilite/},
year = {2019}
}